Have you ever come across the words “commutative diagram” before? Perhaps you’ve read or heard someone utter a sentence that went something like
“For every [bla bla] there existsa [yadda yadda] such that the following diagram commutes.”
and perhaps it left you wondering what it all meant. I was certainly mystified when I first came across a commutative diagram. And it didn’t take long to realize that the phrase “the following diagram commutes” was (and is) quite ubiquitous. It appears in theorems, propositions, lemmas and corollaries almost everywhere!
So what’s the big deal with diagrams? And what does commute mean anyway?? It turns out the answer is quite simple.
Do you know what a composition of two functions is?
Then you know what a commutative diagram is!
A commutative diagram is simply the picture behind function composition.
Truly, it is that simple. To see this, suppose AA and BB are sets and ff is a function from AA to BB. Since ff maps (i.e. assigns) elements in AA to elements in BB, it is often helpful to denote that process by an arrow.
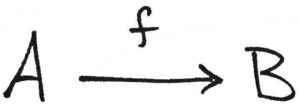
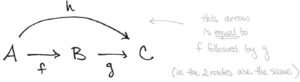
And there you go. That’s an example of a diagram. But suppose we have another function gg from sets BB to CC, and suppose ff and gg are composable. Let’s denote their composition by h=g∘fh=g∘f. Then both gg and hh can be depicted as arrows, too.

But what is the arrow A→CA→C really? I mean, really? Really it’s just the arrows ff and gg lined up side-by-side.
But maybe we think that drawing hh’s arrow curved upwards like that takes up too much space, so let’s bend the diagram a bit and redraw it like this:
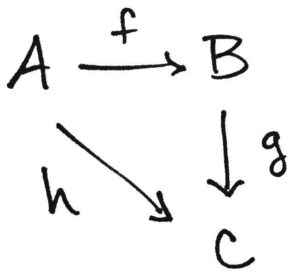
This little triangle is the paradigm example of a commutative diagram. It’s a diagram because it’s a schematic picture of arrows that represent functions. And it commutes because the diagonal function IS EQUAL TO the composition of the vertical and horizontal functions, i.e. h(a)=g(f(a))h(a)=g(f(a)) for every a∈Aa∈A. So a diagram “commutes” if all paths that share a common starting and ending point are the same. In other words, your diagram commutes if it doesn’t matter how you commute from one location to another in the diagram.
But be careful.
Not every diagram is a commutative diagram.
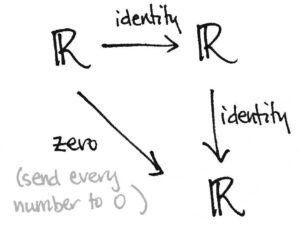
The picture on the right is a bona fide diagram of real-valued functions, but it is defintitely not commutative. If we trace the number 11 around the diagram, it maps to 00 along the diagonal arrow, but it maps to 11 itself if we take the horizontal-then-vertical route. And 0≠10≠1. So to indicate if/when a given diagram is commutative, we have to say it explicitly. Or sometimes folks will use the symbols shown below to indicate commutativity:

I think now is a good time to decode another phrase that often accompanies the commutative-diagram parlance. Returning to our f,g,hf,g,h example, we assumed that f,gf,g and h=g∘fh=g∘f already existed. But suppose we only knew about the existence of f:A→Bf:A→B and some other map, say, z:A→Cz:A→C. Then we might like to know, “Does there exist a map g:B→Cg:B→C such that z=g∘fz=g∘f? Perhaps the answer is no. Or perhaps the answer is yes, but only under certain hypotheses.* Well, if such a gg does exists, then we’ll say “…there exists a map gg such that the following diagram commutes:

but folks might also say
“…there exists a map gg such that zz factors through gg”
The word “factors” means just what you think it means. The diagram commutes if and only if z=g∘fz=g∘f, and that notation suggests that we may think of gg as a factor of zz, analogous to how 22 is a factor of 66 since 6=2⋅36=2⋅3.
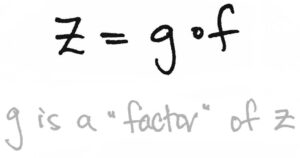
By the way, we’ve only chatted about sets and functions so far, but diagrams make sense in any context in which you have mathematical objects and arrows. So we can talk about diagrams of groups and group homomorphisms, or vector spaces and linear transformations, or topological spaces and continuous maps, or smooth manifolds and smooth maps, or functors and natural transformations and so on. Diagrams make sense in any category. And as you can imagine, there are more complicated diagrams than triangular ones. For instance, suppose we have two more maps i:A→Di:A→D and j:D→Cj:D→C such that hh is equal to not only g∘fg∘f but also j∘ij∘i. Then we can express the equality g∘f=h=j∘ig∘f=h=j∘i by a square:
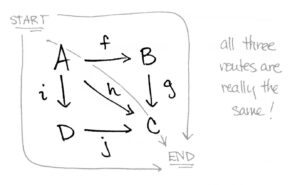
Again, commutativity simply tells us that the three ways of getting from AA to CC are all equivalent. And diagrams can get really crazy and involve other shapes too. They can even be three-dimensional! Here are some possibilities where I’ve used bullets in lieu of letters for the source and target of the arrows.
No matter the shape, the idea is the same: Any map can be thought of as a path or a process from AA to BB, from start to finish. And we use diagrams to capitalize on that by literally writing down “AA” and “BB” (or “∙∙” and “∙∙”) and by literally drawing a path—in the form of an arrow—between them.
For more such insights, log into www.international-maths-challenge.com.
*Credit for article given to Tai-Danae Bradley*