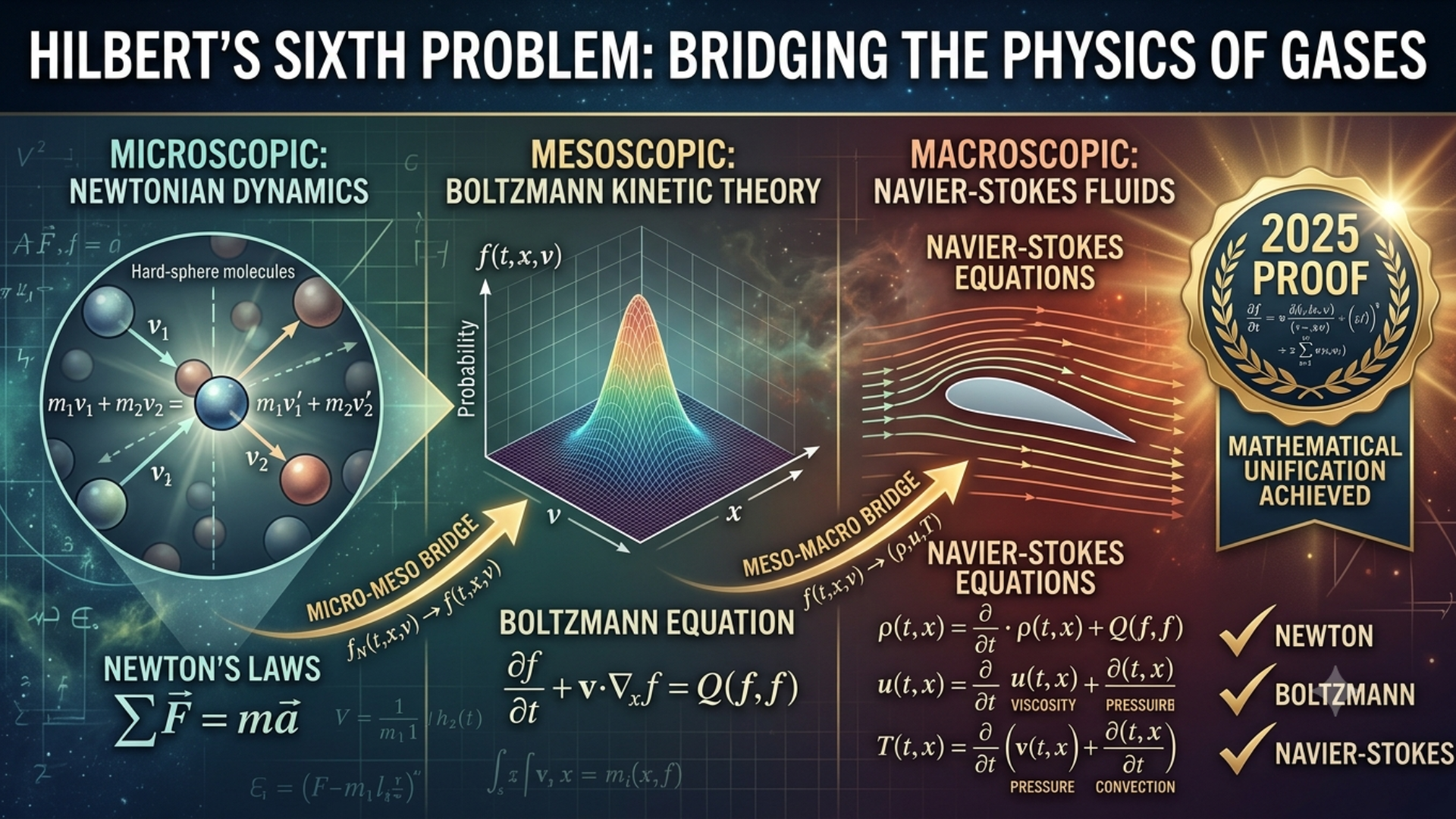
Typical algorithms for doing square roots by hand require estimation. I have taught a different algorithm that does not rely on estimation but instead uses subtraction of successive odd integers. First, I offer examples that illustrate two situations that may arise. Then I present a third situation (as well as how to deal with the square roots of non-perfect squares).

This approach is based on the fact that the nth perfect square is the sum of the first n odd integers. This fact can be used to subtract successive odd integers from a given number for which one wishes to find the square root. If the number isn’t a perfect square, this method can be extended by adding pairs of zeroes to the original number and continuing the process for each additional decimal place one wishes find.
FIRST RULE
It helps to look at a couple of examples to illustrate two “special cases” that arise with some numbers, requiring one or two additional “rules” or steps.
Using the example of 54,756:
Start by marking pairs of digits from the right-most digit: 5 | 47 | 56
Then subtract 1 from the leftmost digit or pair: 5 – 1 = 4.
Continue with the next odd integer: 4 – 3 = 1.
We can’t subtract 5 from 1, so we count how many odd integers we’ve subtracted thus far (2) and mark that above the 5.
Bring down the next pair of digits and append it to the 1 yielding 147.
To get the next odd integer to subtract, multiply the last odd integer subtracted by 10 and add 11 (this is Rule #1) to the product. Here, we have 10 x 3 + 11 = 41. Proceed as previously, subtracting 41 from 147 = 106.
Subtract the next odd integer, 43 from 106 = 63.
Subtract the next odd integer, 45 from 63 = 18.
Again, we can’t subtract 47 from 18; counting, we have done 3 subtractions and place 3 above the pair 47. Multiply 45 x 10 and add 11 = 461.
Bring down the next pair of digits, 56, and append them to the 18, yielding 1856.
Subtract 461 from 1856 = 1395.
Subtract the next odd integer, 463 from 1395 = 932.
Subtract the next odd integer, 465 from 932 = 467.
Subtract the next odd integer, 467 from 467 = 0.
Stop.
Counting how many subtractions, we see it is 4 and we write 4 above the 56.
Our answer is that 234 is the square root of 54,756. Alternately, instead of keeping a running total of the subtractions and placing the digits above successive pairs of digits from the left, take the last number subtracted, 467, add 1, and divide the result by 2 = 234, same as what we determined the other way.
SECOND RULE
A second example introduces another rule not previously required: find the square root of 4,121,062,016 using the subtraction of successive odd integers.
Begin as above by making pairs of digits from the right-most digit: 4 | 12 | 10 | 62 | 40 | 16
Subtract 1 from 4 = 3.
Subtract 3 from 3 = 0.
Write down 2 for the two subtractions above the 4.
Bring down the next pair of digits, 12.
Multiply 3 x 10 and add 11 = 41.
Note that 41 is too big to subtract from 12.
Write 0 above the 12, since we did 0 subtractions.
Bring down the next pair of digits, 10, and append to the 12 => 1210.
Insert a 0 to the left of the last digit in 41 => 401. (This is Rule #2)
Subtract 401 from 1210 = 809.
Subtract the next odd integer, 403, from 809 = 406.
Subtract the next odd integer, 405 from 406 = 1.
For the three subtractions, write 3 above the 10.
Bring down the next pair of integers, 62 and append to the 1 => 162
Multiply 405 by 10 and add 11 = 4061.
We need to apply Rule #2 again. Write 0 above the 62, bring down the next pair of digits, 40, and append to the 162 => 16240.
Insert 0 to the left of the last digit of 4061 => 40601.
Note that this is still too big to subtract from 16240.
Apply Rule #2 again (and it may have to be applied more than twice in particular cases).
Write 0 above the 40, bring down the 16 and append to the 16240 => 1624016.
Insert a 0 to the left of the last digit of 40601 => 406001.
Subtract 406001 from 1624016 = 1218015.
Subtract the next odd integer , 406003 from 1218015 = 812012.
Subtract the next odd integer, 406005 from 812012 = 406007.
Subtract the next odd integer, 406007 from 406007 = 0.
Write a 4 above the last pair of digits, 16.
The square root of 41210624016 = 203,004.
Again, alternately, the answer = (406007+1) / 2 = 203,004.
THIRD RULE
There is a group of numbers for which the process previously described won’t work. For example, try to use it to find the square root of 100.
Grouping as before: 1 | 00
Subtracting 1 from 1 = 0.
Write 1 above the 1, bring down the next pair of digits, 00, and append to the 0.
Multiply 1 x 10 and add 11 = 21.
Can’t subtract 21 from 0. Hmm. Although we know the answer is 10, to make things work, we can note the following, which is Rule #3:
If you want the square root of a whole number that ends in two or more zeros, write the number as a product of a number and an even power of ten.
So 100 = 1 x 10^2.
We get that the square root of 1 = 1, append one zero for every pair of zeroes in the original number, and Bob’s your uncle. (Or something like that).
For example, to find the square root of 3,610,000, remove two pairs of zeroes from the original number, then apply the original procedure:
Group: 3 | 61.
Subtract 1 from 3 = 2
Can’t subtract 3 from 2, so write 1 above the 3, bring down the next pair of digits and append them to the 2 => 261.
Multiply 1 x 10 and add 11 = 21.
Subtract 21 from 261 = 240.
Subtract 23 from 240 = 217
Subtract 25 from 217 = 192
Subtract 27 from 192 = 165
Subtract 29 from 165 = 136
Subtract 31 from 136 = 105
Subtract 33 from 105 = 72
Subtract 35 from 72 = 37
Subtract 37 from 37 = 0
So write a 9 above the 61. Append two zeroes to the 19, one for each pair removed.
Then the square root of 3,610,000 = 1900.
DEALING WITH NON-PERFECT SQUARES
Finally, this process works for whole numbers that aren’t perfect squares and for decimals. It just won’t terminate in those cases (except arbitrarily). For a decimal, also break the number into pairs of digits to the right of the decimal point.
For example, finding the square root of 3 to 3 decimal places.
Append pairs of zeroes for each decimal place you want in the answer, plus two more to be able to round to the given place.
So write 3 as 3 | 00 | 00 | 00 | 00
Subtract 1 from 3 = 2.
Write 1 above the 3. Bring down a pair of zeroes, append to the 2 => 200.
Multiply 1 x 10 and add 11 = 21.
Subtract 21 from 200 = 179
Subtract 23 from 179 = 156
Subtract 25 from 156 = 131
Subtract 27 from 131 = 104
Subtract 29 from 104 = 75
Subtract 31 from 75 = 44
Subtract 33 from 44 = 11.
Write 7 above the first pair of zeroes.
Bring down the next pair of zeroes and append to the 11 => 1100.
Multiply 33 x 10 and add 11 = 341.
Subtract 341 from 1100 = 759.
Subtract 343 from 759 = 416.
Subtract 345 from 416 = 71.
Write 3 above the second pair of zeroes.
Append the next pair of zeroes to the 71 => 7100.
Multiply 345 x 10 and add 11 = 3461.
Subtract 3461 from 7100 = 3639.
Subtract 3463 from 3639 = 176.
Write 2 above the third pair of zeroes.
Append the last pair of zeroes to the 176 => 17600
Multiply 3463 x 10 and add 11 = 346241.
We could continue, but it suffices to realize that the next digit will be 0 and so our answer is that the square root of 3 is 1.732 rounded to three decimal places.
For more such insights, log into www.international-maths-challenge.com.
*Credit for article given to Michael Goldenberg*