Pi defines the relationship between a circle’s radius and its area.
Some people have argued that Pi’s days are numbered and that other tools, such as tau, could do its job more efficiently. As someone who has studied Pi throughout his entire working life, my response to such challenges is unwavering: Pi is the gift that keeps on giving.
People call me Doctor Pi. I have played with Pi since I was a child and have studied it seriously for 30 years. Each year I discover new, unexpected and amusing things about Pi, its history and its computation. I never tire of it.
Erm, what is Pi?
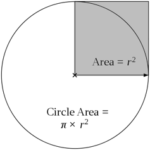
Pi, written with the Greek letter π, has the value of 3.14159 …, is the most important number in mathematics. The area of a circle of radius r is πr2 while the perimeter has length 2πr.
Some Pi facts? OK
- Without Pi there is no theory of motion, no understanding of geometry or space/time.
- Pi occurs in important fields of applied mathematics.
- Pi is used throughout engineering, science and medicine and is studied for its own sake in number theory.
- It fascinates specialists and hobbyists alike.
The history of Pi is a history of mathematics
The most famous names in mathematics – Leibniz, Euler, Gauss, Riemann – all play their part in Pi’s illustrious history. In approximately 250BCE Archimedes of Syracuse rigorously showed that the area of a circle is Pi times the square of its radius.
Isaac Newton computed Pi to at least 15 digits in 1666 and a raft of new formulas for calculating Pi in the intervening years have vastly expanded our understanding of this irrational, irreplaceable number.
In my capacity as Doctor Pi – an affectionate name given to me by my students and colleagues – I have met Nobel Prize winners, pop stars and variety of colourful characters, many of whom go potty for this number.
So why the broad attraction? What is the secret of Pi’s enduring appeal? It appears in The Simpsons (doh!), in Star Trek (beam me up!), and in British singer-songwriter Kate Bush’s lovely 2005 song Pi:
“Sweet and gentle and sensitive man With an obsessive nature and deep fascination for numbers And a complete infatuation with the calculation of Pi.”
In the song’s refrain, Bush recites the first 160 digits of Pi (but messes up after 50!) Pi shows up in the movie The Matrix, episodes of Law and Order, and Yann Martel’s Mann-Booker prize winning 2001 novel Life of Pi. No other piece of mathematics can command such attention.
Memorising Pi
The current Guinness World Record for reciting these by rote is well in excess of 60,000 digits.
This is particularly impressive when you consider that Pi, having been proven irrational in the 18th century, has no known repetition or pattern within its infinite decimal representation.
A former colleague of mine, Simon Plouffe, was a Guinness World Record-holder a generation ago, after reciting Pi to approximately 4,700 digits.
Not surprisingly, there is a trend towards building mnemonics whereby the number of letters in a given word represents a digit in the series. For example “How I need a drink, alcoholic of course” represents 3.1415926. This mnemonic formed the basis of a Final Jeopardy! question in 2005.
Some mnemonics are as long as 4,000 digits, but my current favourite is a 33-digit self-referrent mnemonic published in New Scientist on Pi Day (March 14) last year.
Is Pi really infinite?
In a word: yes. So far, it has been calculated to five trillion (5,000,000,000,000) digits. This record was set in August 2010 on Shigeru Kondo’s US$18,000 homemade computer using software written by American university student Alex Yee.
Each such computation is a tour-de-force of computing science.
Estimates suggest that within the next ten to 15 years a quadrillion (1,000,000,000,000,000) digits of Pi will probably be computed. As relatively-recently as 1961, Daniel Shanks, who himself calculated Pi to over 100,000 digits, declared that computing one billion digits would be “forever impossible”. As it transpired, this feat was achieved in 1989 by Yasumasa Kanada of Japan.
It’s a kind of magic
Although it is very likely we will learn nothing new mathematically about Pi from computations to come, we just may discover something truly startling. Pi has seen off attacks in the past. It will see off attacks in the future. Pi, like its inherent magic, is infinite.
The battle continues.
For more such insights, log into www.international-maths-challenge.com.
*Credit for article given to Jonathan Borwein (Jon)*