One of the essential skills students need to master in primary school mathematics are “multiplication facts.”
What are they? What are they so important? And how can you help your child master them?
What are multiplication facts?
Multiplication facts typically describe the answers to multiplication sums up to 10×10. Sums up to 10×10 are called “facts” as it is expected they can be easily and quickly recalled. You may recall learning multiplication facts in school from a list of times tables.
The shift from “times tables” to “multiplication facts” is not just about language. It stems from teachers wanting children to see how multiplication facts can be used to solve a variety of problems beyond the finite times table format.
For example, if you learned your times tables in school (which typically went up to 12×12 and no further), you might be stumped by being asked to solve 15×8 off the top of your head. In contrast, we hope today’s students can use their multiplication facts knowledge to quickly see how 15×8 is equivalent to 10×8 plus 5×8.
The shift in terminology also means we are encouraging students to think about the connections between facts. For example, when presented only in separate tables, it is tricky to see how 4×3 and 3×4 are directly connected.
Math education has changed
In a previous piece, we talked about how mathematics education has changed over the past 30 years.
In today’s mathematics classrooms, teachers still focus on developing students’ mathematical accuracy and fast recall of essential facts, including multiplication facts.
But we also focus on developing essential problem-solving skills. This helps students form connections between concepts, and learn how to reason through a variety of real-world mathematical tasks.
Why are multiplication facts so important?
By the end of primary school, it is expected students will know multiplication facts up to 10×10 and can recall the related division fact (for example, 10×9=90, therefore 90÷10=9).
Learning multiplication facts is also essential for developing “multiplicative thinking.” This is an understanding of the relationships between quantities, and is something we need to know how to do on a daily basis.
When we are deciding whether it is better to purchase a 100g product for $3 or a 200g product for $4.50, we use multiplicative thinking to consider that 100g for $3 is equivalent to 200g for $6—not the best deal!
Multiplicative thinking is needed in nearly all math topics in high school and beyond. It is used in many topics across algebra, geometry, statistics and probability.
This kind of thinking is profoundly important. Research shows students who are more proficient in multiplicative thinking perform significantly better in mathematics overall.
In 2001, an extensive RMIT study found there can be as much as a seven-year difference in student ability within one mathematics class due to differences in students’ ability to access multiplicative thinking.
These findings have been confirmed in more recent studies, including a 2021 paper.
So, supporting your child to develop their confidence and proficiency with multiplication is key to their success in high school mathematics. How can you help?
Below are three research-based tips to help support children from Year 2 and beyond to learn their multiplication facts.
- Discuss strategies
One way to help your child’s confidence is to discuss strategies for when they encounter new multiplication facts.
Prompt them to think of facts they already and how they can be used for the new fact.
For example, once your child has mastered the x2 multiplication facts, you can discuss how 3×6 (3 sixes) can be calculated by doubling 6 (2×6) and adding one more 6. We’ve now realized that x3 facts are just x2 facts “and one more”!
Strategies can be individual: students should be using the strategy that makes the most sense to them. So you could ask a questions such as “if you’ve forgotten 6×7, how could you work it out?” (we might personally think of 6×6=36 and add one more 6, but your child might do something different and equally valid).
This is a great activity for any quiet car trip. It can also be a great drawing activity where you both have a go at drawing your strategy and then compare. Identifying multiple strategies develops flexible thinking.
- Help them practice
Practicing recalling facts under a friendly time crunch can be helpful in achieving what teachers call “fluency” (that is, answering quickly and easily).
A great game you could play with your children is “multiplication heads up” . Using a deck of cards, your child places a card to their forehead where you can see but they cannot. You then flip over the top card on the deck and reveal it to your child. Using the revealed card and the card on your child’s head you tell them the result of the multiplication (for example, if you flip a 2 and they have a 3 card, then you tell them “6!”).
Based on knowing the result, your child then guesses what their card was.
If it is challenging to organize time to pull out cards, you can make an easier game by simply quizzing your child. Try to mix it up and ask questions that include a range of things they know well with and ones they are learning.
Repetition and rehearsal will mean things become stored in long-term memory.
- Find patterns
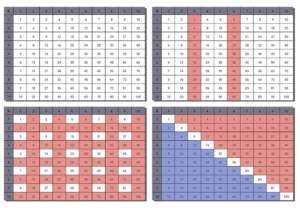
Another great activity to do at home is print some multiplication grids and explore patterns with your child.
A first start might be to give your child a blank or partially blank multiplication grid which they can practice completing.
Then, using colored pencils, they can color in patterns they notice. For example, the x6 column is always double the answer in the x3 column. Another pattern they might see is all the even answers are products of 2, 4, 6, 8, 10. They can also notice half of the grid is repeated along the diagonal.
This also helps your child become a mathematical thinker, not just a calculator.
The importance of multiplication for developing your child’s success and confidence in mathematics cannot be understated. We believe these ideas will give you the tools you need to help your child develop these essential skills.
For more such insights, log into our website https://international-maths-challenge.com
Credit of the article given to Bronwyn Reid O’Connor and Benjamin Zunica, The Conversation