The tone and tuning of musical instruments has the power to manipulate our appreciation of harmony, new research shows. The findings challenge centuries of Western music theory and encourage greater experimentation with instruments from different cultures.
According to the Ancient Greek philosopher Pythagoras, ‘consonance’—a pleasant-sounding combination of notes—is produced by special relationships between simple numbers such as 3 and 4. More recently, scholars have tried to find psychological explanations, but these ‘integer ratios’ are still credited with making a chord sound beautiful, and deviation from them is thought to make music ‘dissonant,’ unpleasant sounding.
But researchers from the University of Cambridge, Princeton and the Max Planck Institute for Empirical Aesthetics, have now discovered two key ways in which Pythagoras was wrong.
Their study, published in Nature Communications, shows that in normal listening contexts, we do not actually prefer chords to be perfectly in these mathematical ratios.
“We prefer slight amounts of deviation. We like a little imperfection because this gives life to the sounds, and that is attractive to us,” said co-author, Dr. Peter Harrison, from Cambridge’s Faculty of Music and Director of its Center for Music and Science.
The researchers also found that the role played by these mathematical relationships disappears when you consider certain musical instruments that are less familiar to Western musicians, audiences and scholars. These instruments tend to be bells, gongs, types of xylophones and other kinds of pitched percussion instruments. In particular, they studied the ‘bonang,’ an instrument from the Javanese gamelan built from a collection of small gongs.
“When we use instruments like the bonang, Pythagoras’s special numbers go out the window and we encounter entirely new patterns of consonance and dissonance,” Dr. Harrison said.
“The shape of some percussion instruments means that when you hit them, and they resonate, their frequency components don’t respect those traditional mathematical relationships. That’s when we find interesting things happening.”
“Western research has focused so much on familiar orchestral instruments, but other musical cultures use instruments that, because of their shape and physics, are what we would call ‘inharmonic.'”
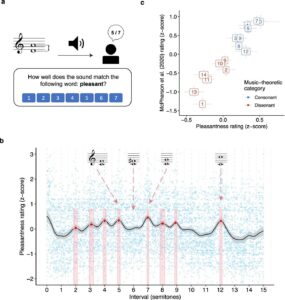
The researchers created an online laboratory in which over 4,000 people from the US and South Korea participated in 23 behavioural experiments. Participants were played chords and invited to give each a numeric pleasantness rating or to use a slider to adjust particular notes in a chord to make it sound more pleasant. The experiments produced over 235,000 human judgments.
The experiments explored musical chords from different perspectives. Some zoomed in on particular musical intervals and asked participants to judge whether they preferred them perfectly tuned, slightly sharp or slightly flat.
The researchers were surprised to find a significant preference for slight imperfection, or ‘inharmonicity.’ Other experiments explored harmony perception with Western and non-Western musical instruments, including the bonang.
Instinctive appreciation of new kinds of harmony
The researchers found that the bonang’s consonances mapped neatly onto the particular musical scale used in the Indonesian culture from which it comes. These consonances cannot be replicated on a Western piano, for instance, because they would fall between the cracks of the scale traditionally used.
“Our findings challenge the traditional idea that harmony can only be one way, that chords have to reflect these mathematical relationships. We show that there are many more kinds of harmony out there, and that there are good reasons why other cultures developed them,” Dr. Harrison said.
Importantly, the study suggests that its participants—not trained musicians and unfamiliar with Javanese music—were able to appreciate the new consonances of the bonang’s tones instinctively.
“Music creation is all about exploring the creative possibilities of a given set of qualities, for example, finding out what kinds of melodies can you play on a flute, or what kinds of sounds can you make with your mouth,” Harrison said.
“Our findings suggest that if you use different instruments, you can unlock a whole new harmonic language that people intuitively appreciate, they don’t need to study it to appreciate it. A lot of experimental music in the last 100 years of Western classical music has been quite hard for listeners because it involves highly abstract structures that are hard to enjoy. In contrast, psychological findings like ours can help stimulate new music that listeners intuitively enjoy.”
Exciting opportunities for musicians and producers
Dr. Harrison hopes that the research will encourage musicians to try out unfamiliar instruments and see if they offer new harmonies and open up new creative possibilities.
“Quite a lot of pop music now tries to marry Western harmony with local melodies from the Middle East, India, and other parts of the world. That can be more or less successful, but one problem is that notes can sound dissonant if you play them with Western instruments.”
“Musicians and producers might be able to make that marriage work better if they took account of our findings and considered changing the ‘timbre,’ the tone quality, by using specially chosen real or synthesized instruments. Then they really might get the best of both worlds: harmony and local scale systems.”
Harrison and his collaborators are exploring different kinds of instruments and follow-up studies to test a broader range of cultures. In particular, they would like to gain insights from musicians who use ‘inharmonic’ instruments to understand whether they have internalized different concepts of harmony to the Western participants in this study.
For more such insights, log into our website https://international-maths-challenge.com
Credit of the article to be given University of Cambridge









