It should come as no surprise that the first recorded use of the number zero, recently discovered to be made as early as the 3rd or 4th century, happened in India. Mathematics on the Indian subcontinent has a rich history going back over 3,000 years and thrived for centuries before similar advances were made in Europe, with its influence meanwhile spreading to China and the Middle East.
As well as giving us the concept of zero, Indian mathematicians made seminal contributions to the study of trigonometry, algebra, arithmetic and negative numbers among other areas. Perhaps most significantly, the decimal system that we still employ worldwide today was first seen in India.
The number system
As far back as 1200 BC, mathematical knowledge was being written down as part of a large body of knowledge known as the Vedas. In these texts, numbers were commonly expressed as combinations of powers of ten. For example, 365 might be expressed as three hundreds (3×10²), six tens (6×10¹) and five units (5×10⁰), though each power of ten was represented with a name rather than a set of symbols. It is reasonable to believe that this representation using powers of ten played a crucial role in the development of the decimal-place value system in India.
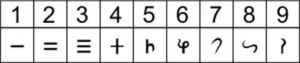
Brahmi numerals. Wikimedia
From the third century BC, we also have written evidence of the Brahmi numerals, the precursors to the modern, Indian or Hindu-Arabic numeral system that most of the world uses today. Once zero was introduced, almost all of the mathematical mechanics would be in place to enable ancient Indians to study higher mathematics.
The concept of zero
Zero itself has a much longer history. The recently dated first recorded zeros, in what is known as the Bakhshali manuscript, were simple placeholders – a tool to distinguish 100 from 10. Similar marks had already been seen in the Babylonian and Mayan cultures in the early centuries AD and arguably in Sumerian mathematics as early as 3000-2000 BC.
But only in India did the placeholder symbol for nothing progress to become a number in its own right. The advent of the concept of zero allowed numbers to be written efficiently and reliably. In turn, this allowed for effective record-keeping that meant important financial calculations could be checked retroactively, ensuring the honest actions of all involved. Zero was a significant step on the route to the democratisation of mathematics.
These accessible mechanical tools for working with mathematical concepts, in combination with a strong and open scholastic and scientific culture, meant that, by around 600AD, all the ingredients were in place for an explosion of mathematical discoveries in India. In comparison, these sorts of tools were not popularised in the West until the early 13th century, though Fibonnacci’s book liber abaci.
Solutions of quadratic equations
In the seventh century, the first written evidence of the rules for working with zero were formalised in the Brahmasputha Siddhanta. In his seminal text, the astronomer Brahmagupta introduced rules for solving quadratic equations (so beloved of secondary school mathematics students) and for computing square roots.
Rules for negative numbers
Brahmagupta also demonstrated rules for working with negative numbers. He referred to positive numbers as fortunes and negative numbers as debts. He wrote down rules that have been interpreted by translators as: “A fortune subtracted from zero is a debt,” and “a debt subtracted from zero is a fortune”.
This latter statement is the same as the rule we learn in school, that if you subtract a negative number, it is the same as adding a positive number. Brahmagupta also knew that “The product of a debt and a fortune is a debt” – a positive number multiplied by a negative is a negative.
For the large part, European mathematicians were reluctant to accept negative numbers as meaningful. Many took the view that negative numbers were absurd. They reasoned that numbers were developed for counting and questioned what you could count with negative numbers. Indian and Chinese mathematicians recognised early on that one answer to this question was debts.
For example, in a primitive farming context, if one farmer owes another farmer 7 cows, then effectively the first farmer has -7 cows. If the first farmer goes out to buy some animals to repay his debt, he has to buy 7 cows and give them to the second farmer in order to bring his cow tally back to 0. From then on, every cow he buys goes to his positive total.
Basis for calculus
This reluctance to adopt negative numbers, and indeed zero, held European mathematics back for many years. Gottfried Wilhelm Leibniz was one of the first Europeans to use zero and the negatives in a systematic way in his development of calculus in the late 17th century. Calculus is used to measure rates of changes and is important in almost every branch of science, notably underpinning many key discoveries in modern physics.

Leibniz: Beaten to it by 500 years.
But Indian mathematician Bhāskara had already discovered many of Leibniz’s ideas over 500 years earlier. Bhāskara, also made major contributions to algebra, arithmetic, geometry and trigonometry. He provided many results, for example on the solutions of certain “Doiphantine” equations, that would not be rediscovered in Europe for centuries.
The Kerala school of astronomy and mathematics, founded by Madhava of Sangamagrama in the 1300s, was responsible for many firsts in mathematics, including the use of mathematical induction and some early calculus-related results. Although no systematic rules for calculus were developed by the Kerala school, its proponents first conceived of many of the results that would later be repeated in Europe including Taylor series expansions, infinitessimals and differentiation.
The leap, made in India, that transformed zero from a simple placeholder to a number in its own right indicates the mathematically enlightened culture that was flourishing on the subcontinent at a time when Europe was stuck in the dark ages. Although its reputation suffers from the Eurocentric bias, the subcontinent has a strong mathematical heritage, which it continues into the 21st century by providing key players at the forefront of every branch of mathematics.
For more insights like this, visit our website at www.international-maths-challenge.com.
Credit of the article given to Christian Yates



{kind=link}